2025-10-17
1.1 K-modes聚类分析简介
1.2 K-modes聚类分析步骤
1.3 K-modes聚类分析在R中的实现
1.4 K-modes聚类分析实例
1.5 k-prototypes聚类分析
K-means 的局限
K-modes 的改进
由 Huang (1998) 提出,K-modes 将:“均值”改成了“众数”(mode),即每一类在每个特征上的最频繁取值作为簇中心。
“欧氏距离”改成了匹配差异系数,即比较每个属性是否相同,不同计 1,相同计 0。
K-modes 就是K-means 在定性数据上的自然推广。
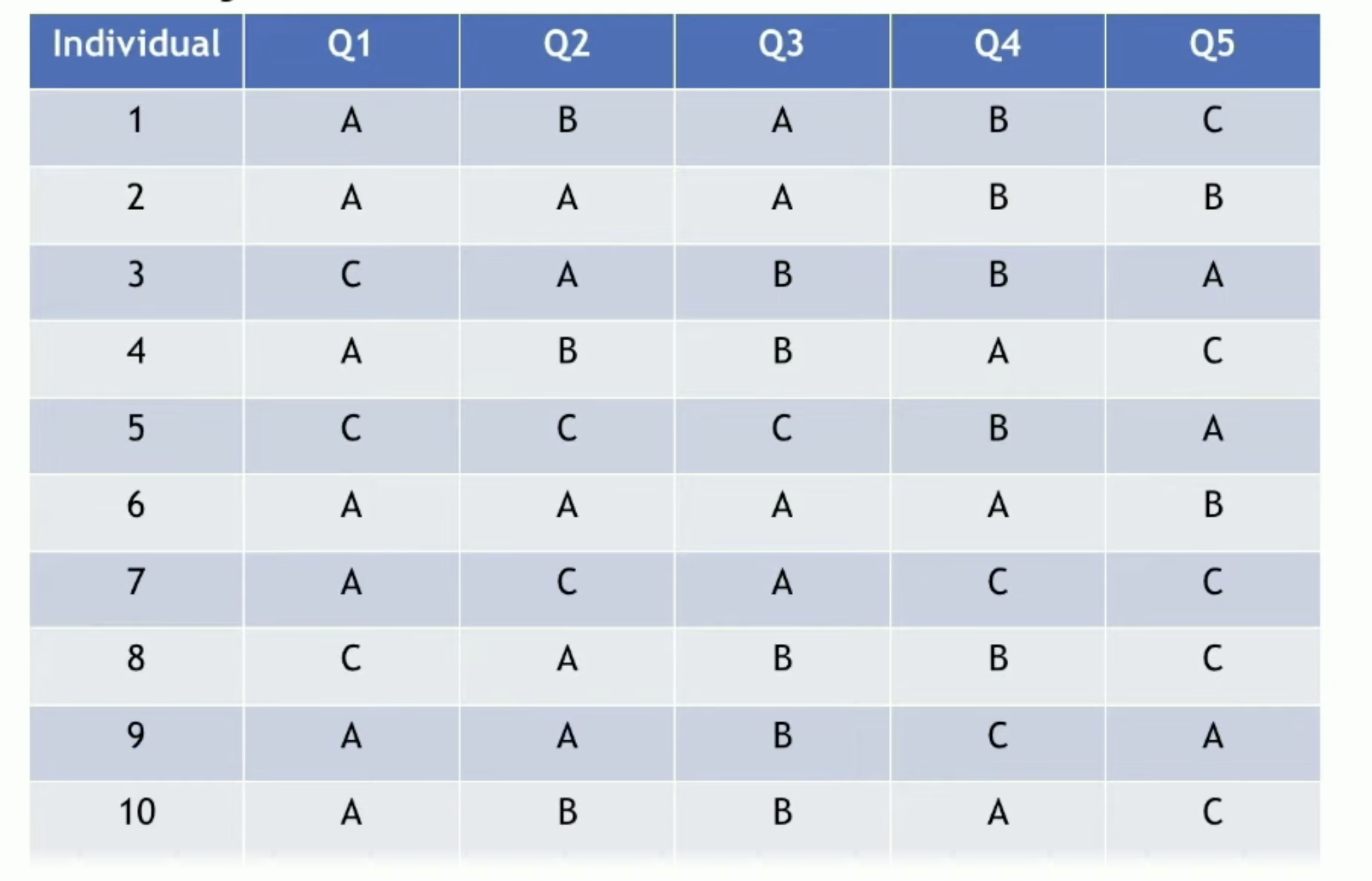
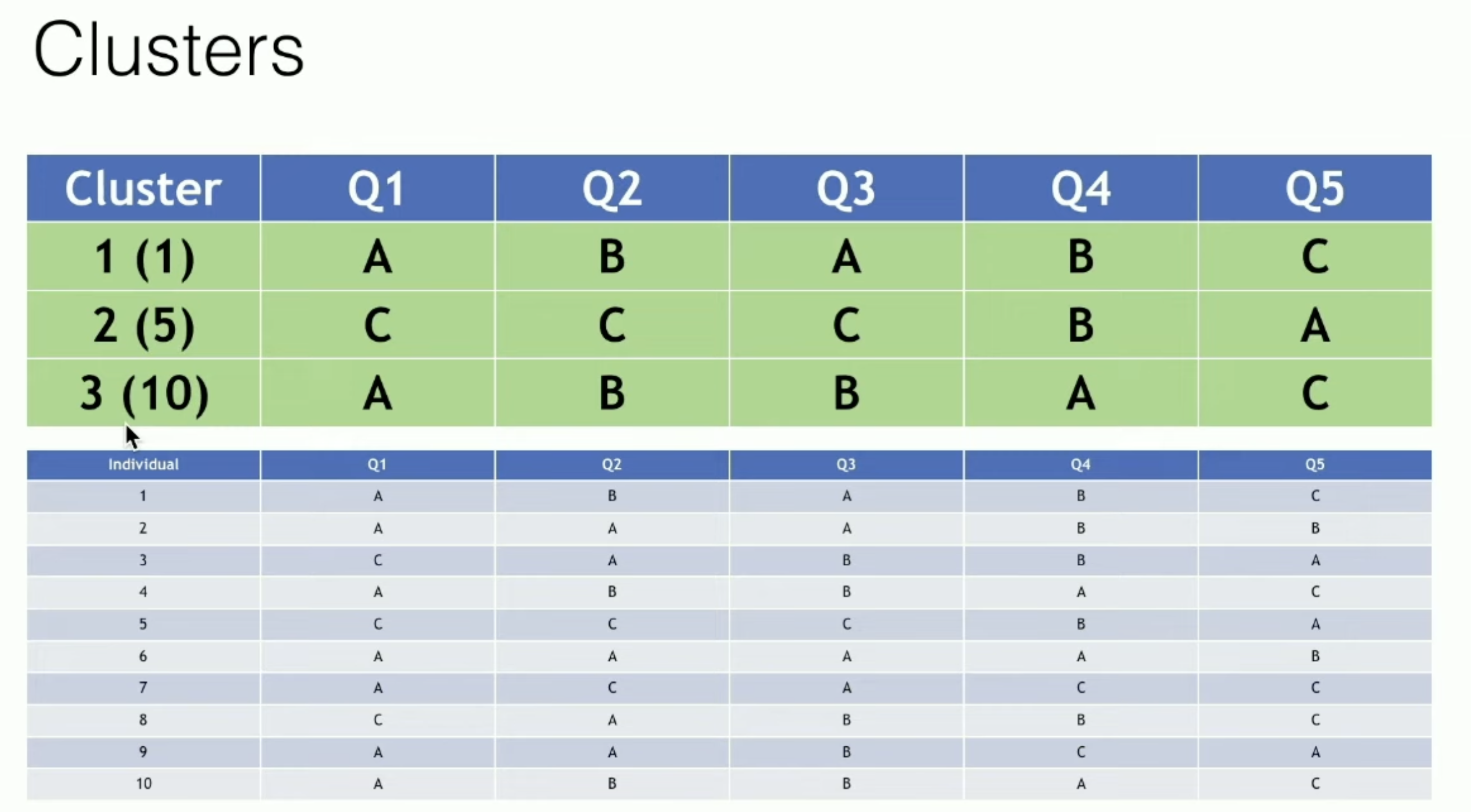
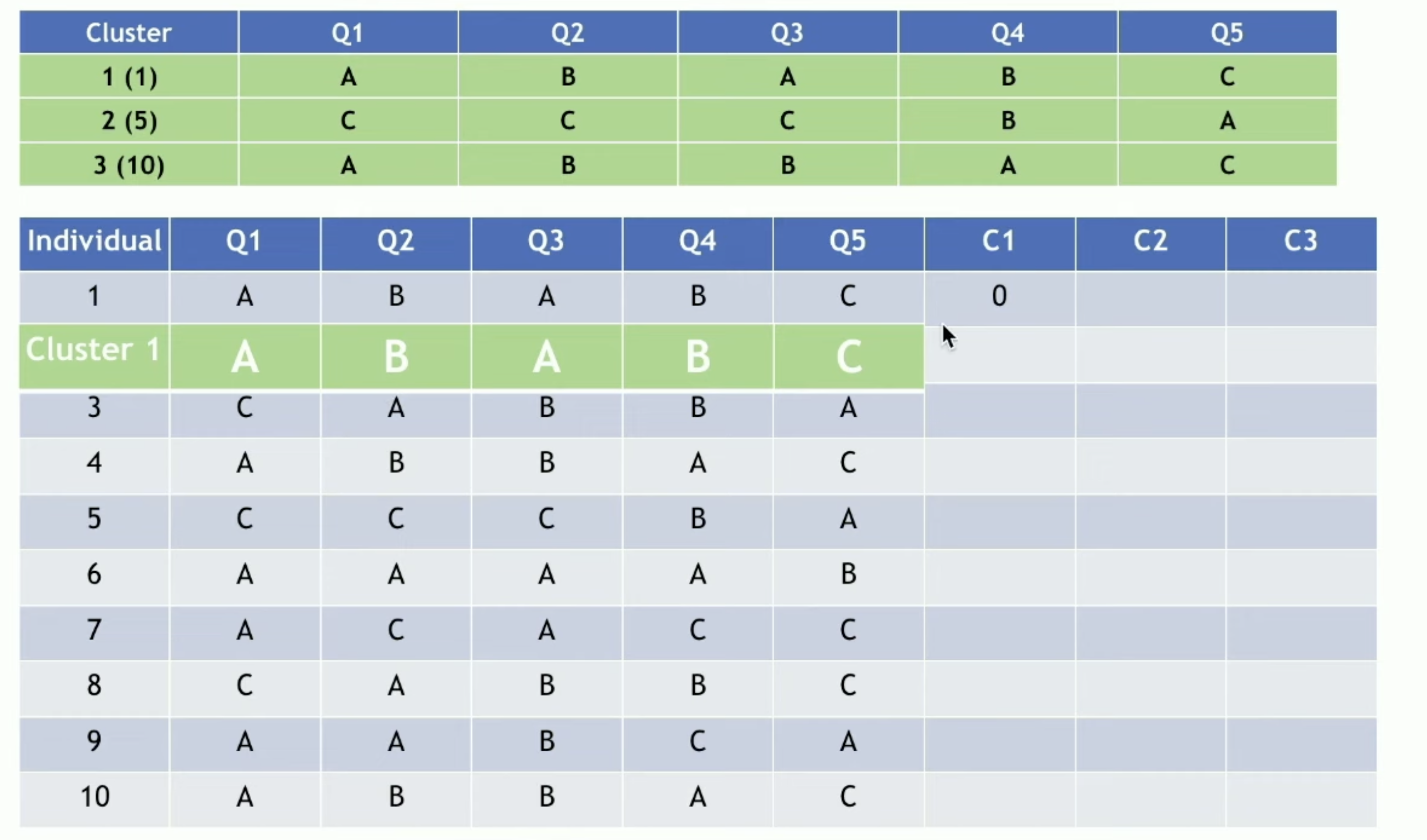
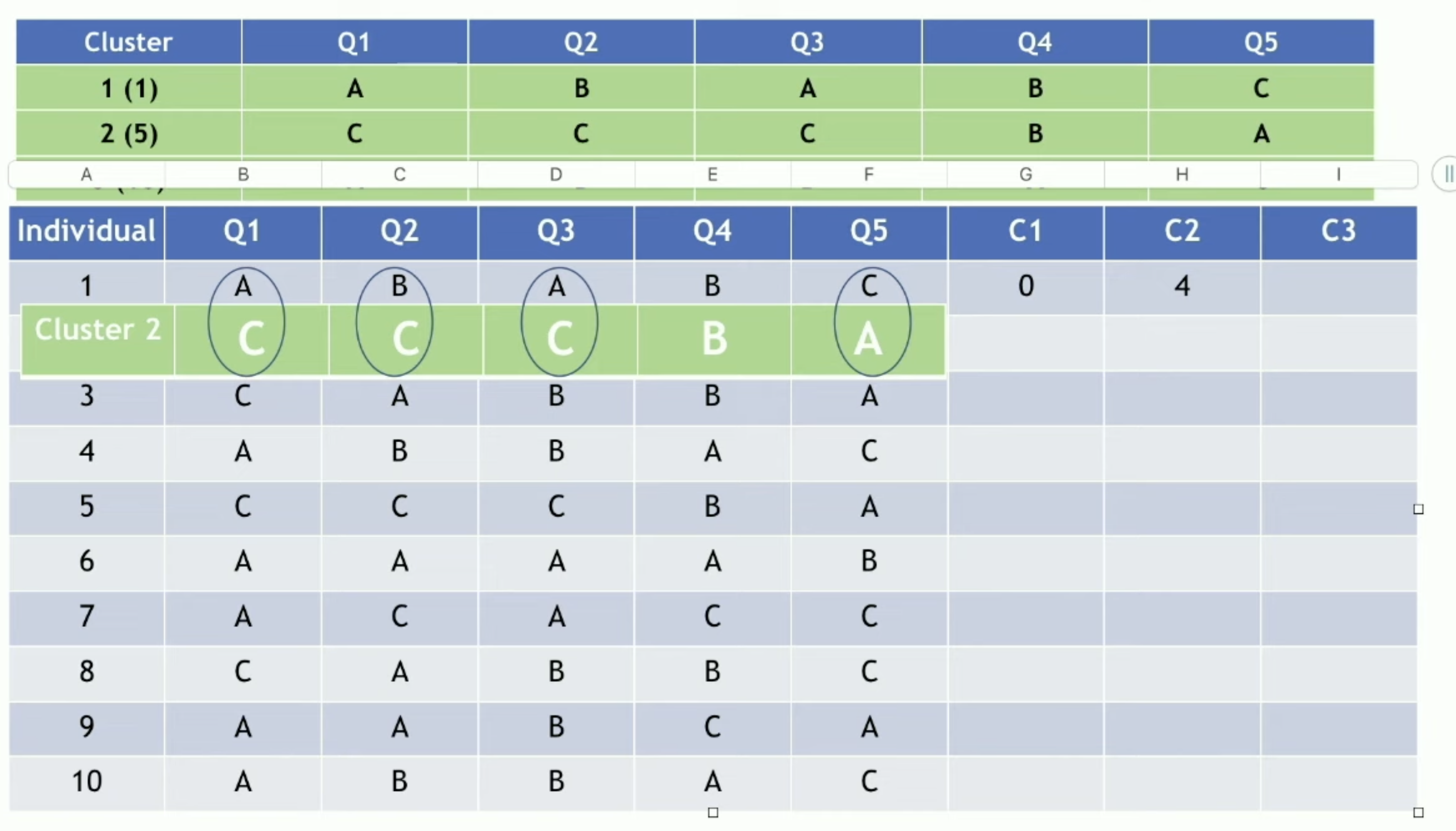
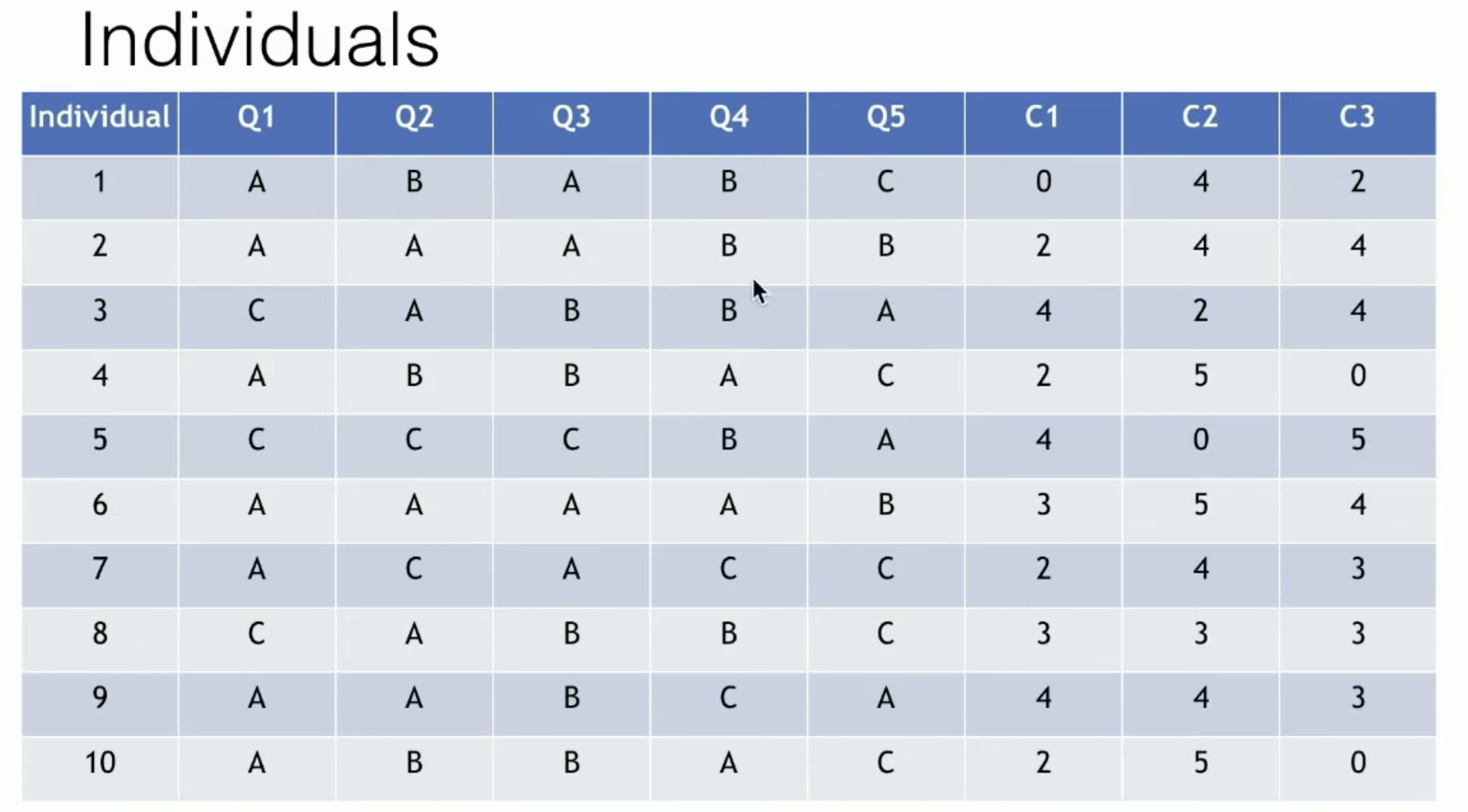
初始化:随机选择K个个案作为初始簇中心
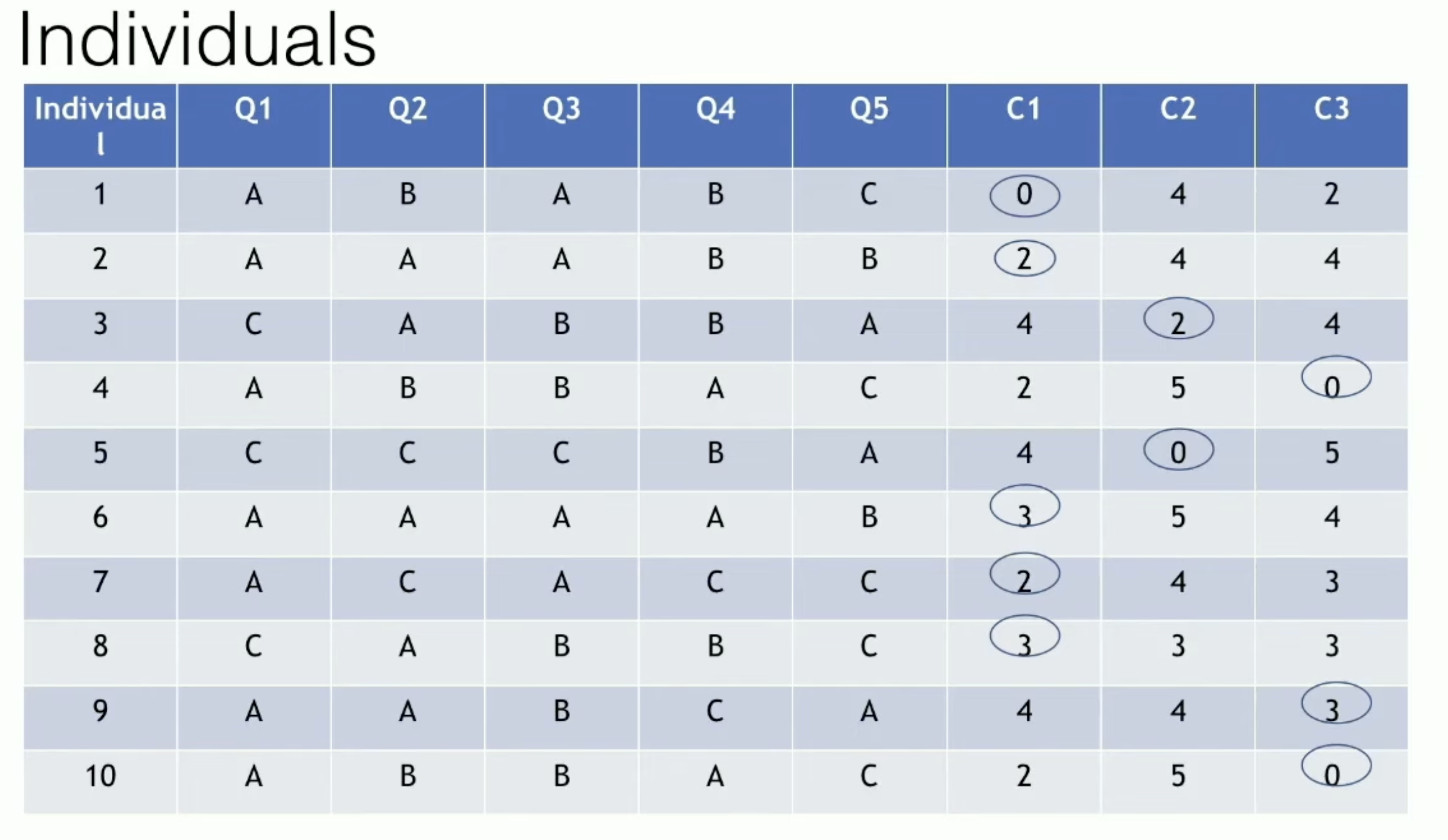
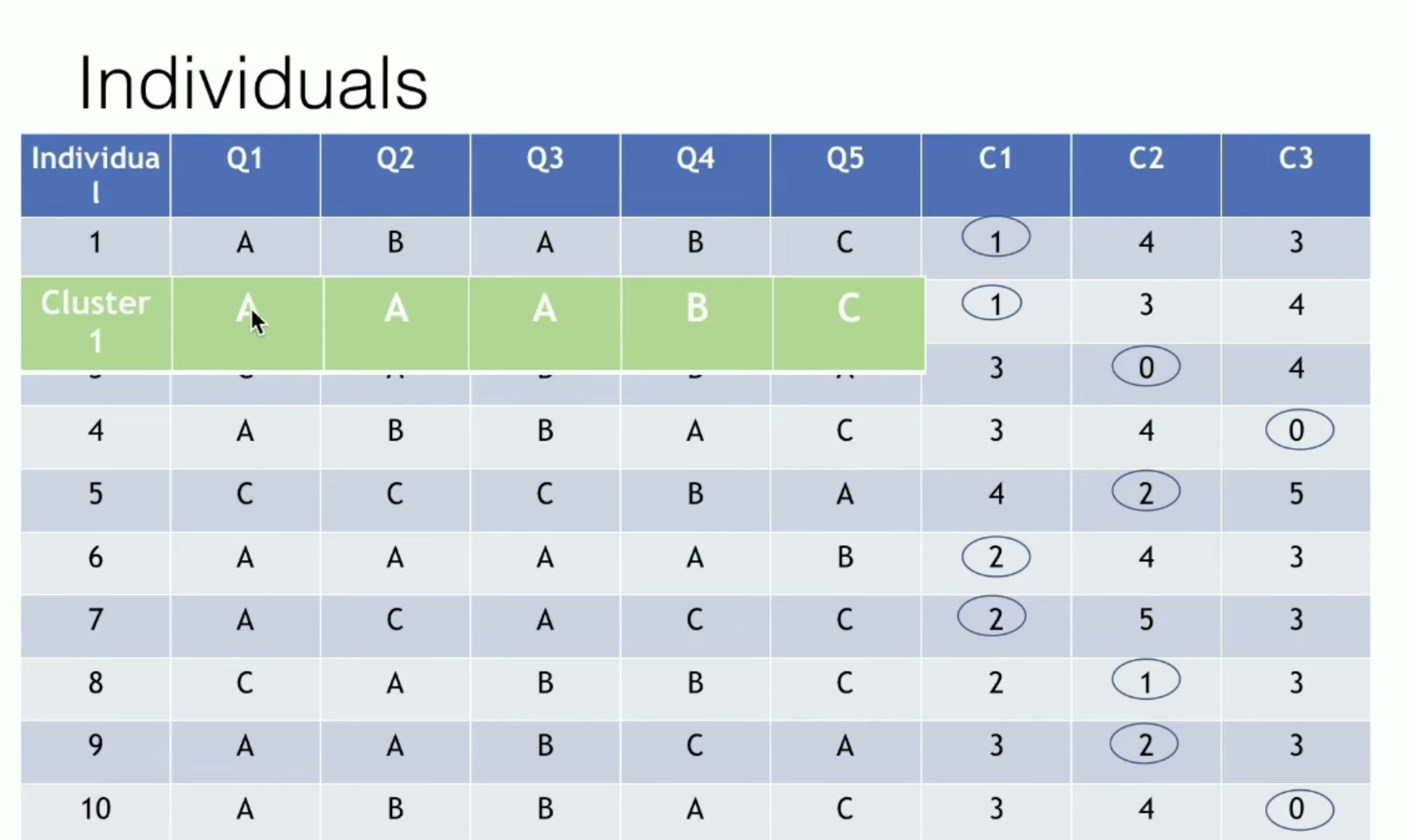
分配步骤:计算每个样本与K个簇中心的距离(匹配差异系数),将样本分配到距离最近的簇
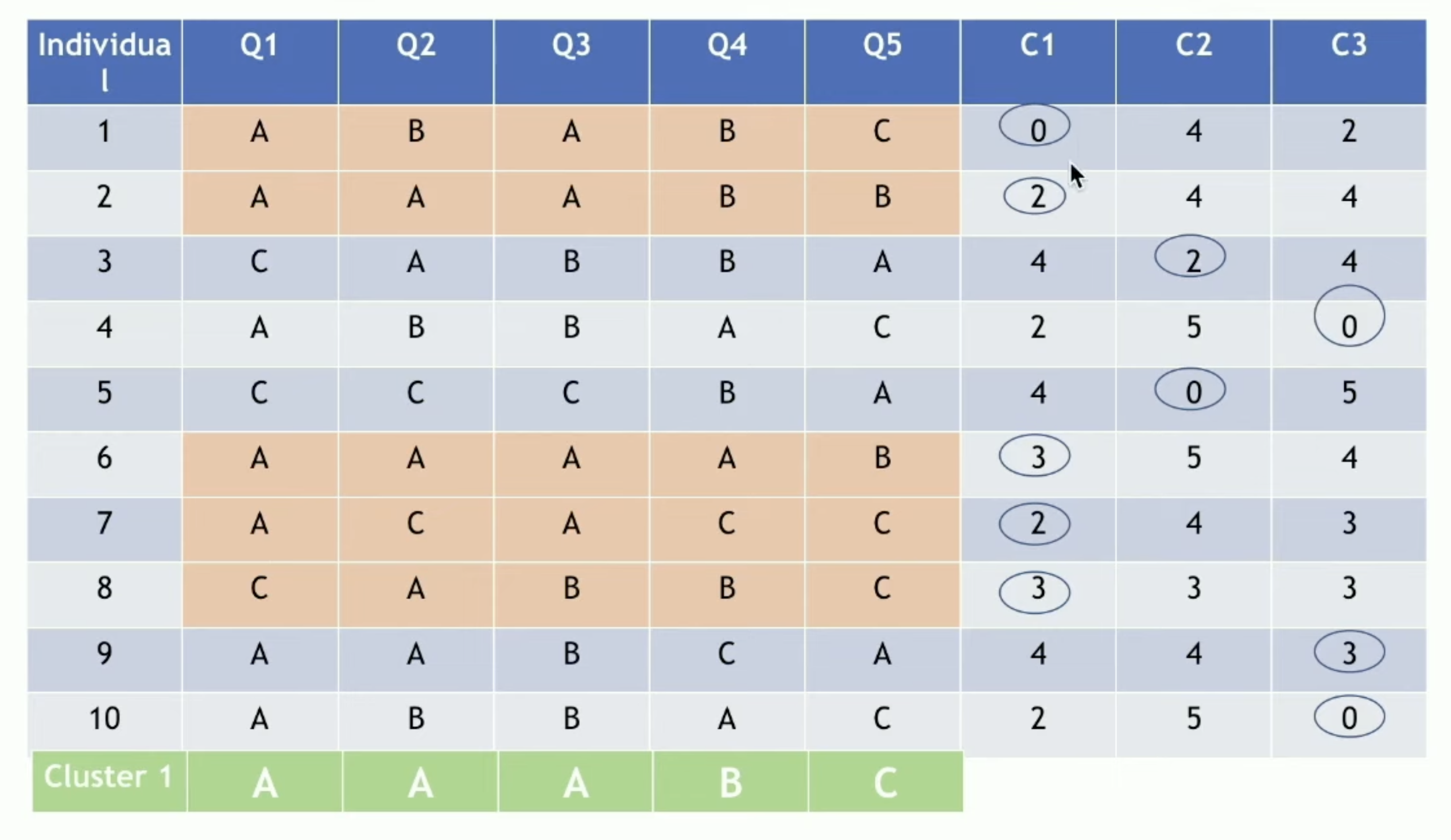
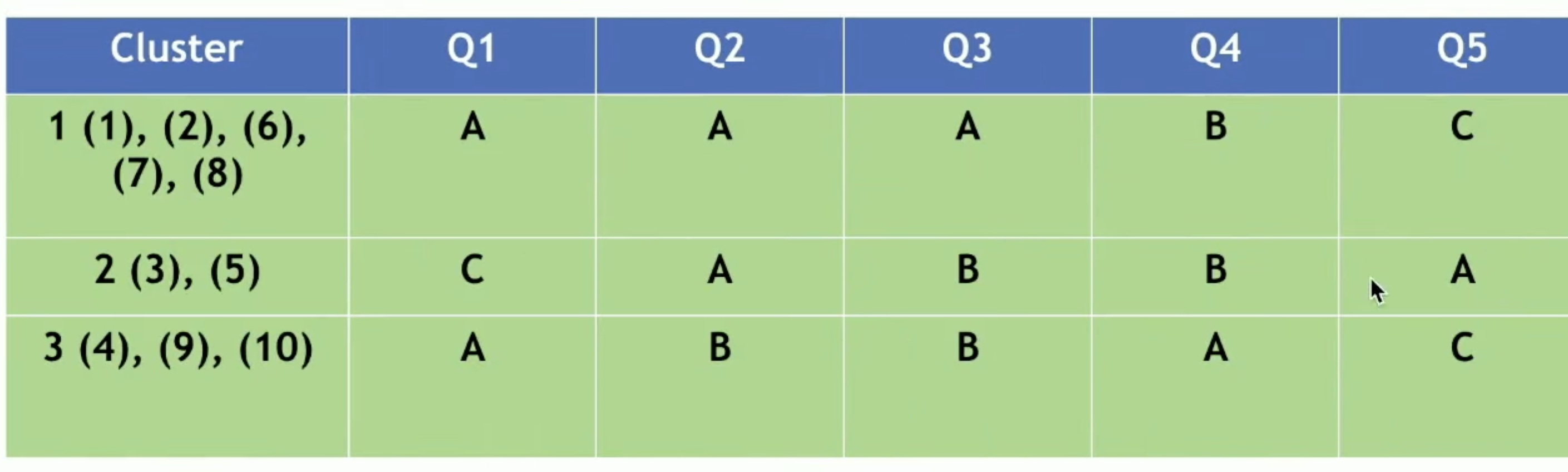
更新步骤:对于每个簇,重新计算簇中心(众数)
重复分配和更新步骤,直到簇中心不再变化或达到最大迭代次数
优点
适用于定性数据
计算效率高,易于实现
能处理大规模数据集
缺点
需要预先指定K值
对初始类中心敏感,可能陷入局部最优
仅适用于定性变量,无法处理混合数据类型
结果解释性较差,难以理解簇的含义
直到簇中心不再变化或达到最大迭代次数
klaR
klaR package
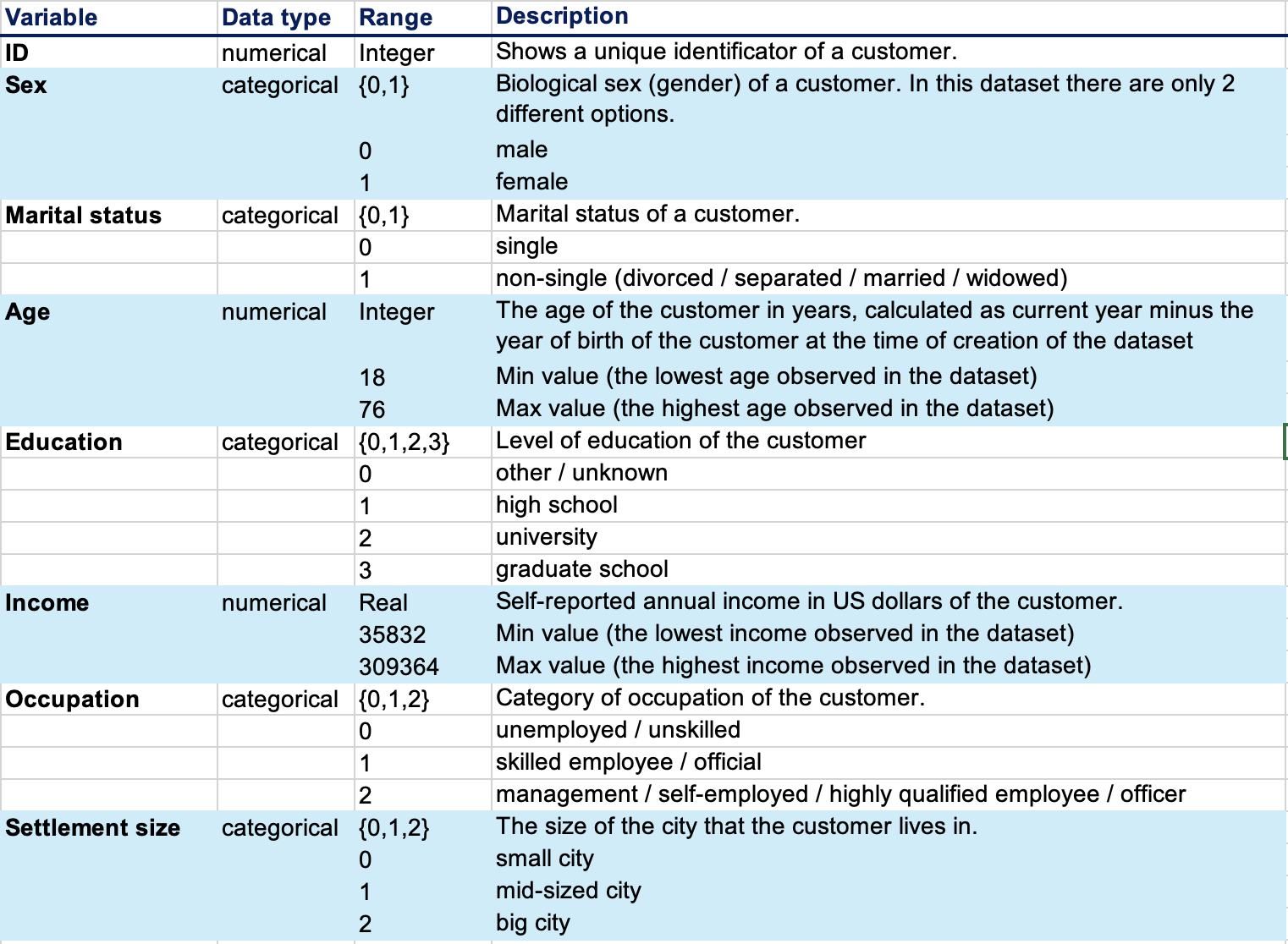
数据简介
数据链接
点击下载数据文件: supermarket.xlsx
kmodes R代码
k-prototypes算法结合了k-means和k-modes的优点,能够同时处理定量和定性变量。
适用于混合数据类型的聚类分析。
通过调整定量和定性变量的权重,可以更灵活地进行聚类。
适用于市场细分、客户分类等实际应用场景。
R包:clustMixType
clustMixType
距离度量
\[ d(x_i, z_j) = \sum_{k \in \text{numerical}}(x_{ik} - z_{jk})^2 + \gamma \sum_{l \in \text{categorical}} \delta(x_{il}, z_{jl}) \]
数值变量使用平方欧氏距离
分类变量使用匹配/不匹配距离(相同=0,不同=1)
γ 为权重系数,用于平衡数值和分类变量
初始化:随机选择K个原型(簇中心),数值部分取均值,分类部分取众数。
分配簇:将每个样本分配给距离最近的簇(使用上面的混合距离度量)。
更新簇中心:
数值变量 → 取簇内均值
分类变量 → 取簇内众数
迭代,直到簇分配不再变化或达到最大迭代次数。
clustMixType package




 点击下载数据文件: supermarket.xlsx
点击下载数据文件: supermarket.xlsx